
大模型時代 LLM
大模型的興起: 從 2022 年底 ChatGPT 的亮相,到 2023 年大模型技術的迅速崛起,再到 DeepSeek 的普及,大模型正以驚人的速度改變世界。2023 年被稱為「大模型元年」。
核心突破: 與以往僅依靠機器邏輯和關鍵字匹配的人工智慧不同,ChatGPT 展現了類人的語言理解與推理能力,能進行自然、富有邏輯與創造性的交流,成為真正的「助手」而非單純工具。
產業影響: 大模型正在重塑教育、科研、新聞、設計、醫療、金融等多個領域,逐漸成為日常生活中不可或缺的夥伴。
全球競爭:
-
- OpenAI:以 GPT 系列引領市場
- Google:鞏固搜尋與 AI 領域霸主地位
- Meta:推動開源大模型,強化社交生態
- 蘋果:提升智慧助手與設備互聯性
- xAI(馬斯克):補齊尖端科技版圖
- Anthropic、DeepSeek、Cohere:以靈活創新策略快速崛起
商業戰略: 各公司目標不同,有的追求技術突破,有的強調生態建設或市場佔領。我在此將深入分析這些策略,揭示背後的商業邏輯。
Context – 內容
- 揭開 AI 革命的四大關鍵真相, 2022 年,人類文明的轉折點.
- 揭開 OpenAI 稱霸 AI 戰場的 5個震撼真相
- 揭秘 Anthropic 挑戰 OpenAI 的五大震撼真相
- 剖析 Google 在 AI 浪潮中的失守與覺醒
- Meta: 驚人的大逆轉:從 470 億美元的元宇宙「學費」,到引領 AI 開源浪潮
- DeepSeek:一場 560 萬美元引發的「AI 民主化」海嘯
- Grok: 揭秘馬斯克 xAI 布局背後的 5 個驚人真相
- AI 反攻:蘋果(Apple)最令人驚訝的五大策略轉向
(1) 從蒸氣機到 ChatGPT:揭開 AI 革命的四大關鍵真相
2022 年,人類文明的轉折點
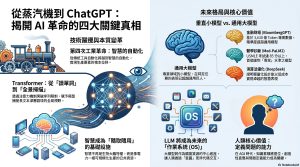
在人類科技史的漫漫長夜中,2022 年底 ChatGPT 的橫空出世,絕非僅是一個新型聊天機器人的誕生,而是一顆「璀璨的新星」瞬間點燃了寂靜的夜空。這道光芒迅速引發了席捲全球的「大模型熱潮」,讓 2023 年被公認為「大模型元年」。
這場變革的底層推動力源於數據與算力的指數級爆發。根據數據顯示,到 2022 年,全球 76 億人口中,每人每天產生的數據量已高達 120GB。在如此龐大的「數據海洋」與計算能力的雙重催化下,人類文明正經歷著一個關鍵的轉折點。這不僅僅是技術的更迭,更是人類歷史上「第四次工業革命」的正式開啟。我們正從單純的工具自動化,跨越到智慧的自動化,這是一場將重塑文明繁榮底層邏輯的全面性革命。
深度真相一:這不是進步,而是「智慧」的第一次工業革命
我們必須以哲學的高度來審視這場變革:這並非傳統意義上的技術進步,而是人類「生產要素的根本位移」。
回望前三次工業革命,本質上都是關於「力量」與「資訊」的延伸:
- 第一次工業革命: 以蒸汽機為核心,實現了「機器替代體力」,解放了人類的雙手。
- 第二次與第三次工業革命: 透過電力與電腦資訊技術,我們自動化了數據的流轉。
而現在發生的第四次工業革命,其核心目標是透過大模型技術對「人類智慧」進行賦能與重塑。這不再只是提升效率,而是實現了「智慧」的數位化與規模化生產。當算力跨越特定閾值,大模型產生了「湧現」現象(Emergence),這意味著決策過程本身開始被機器輔助甚至替代。
金句: 「人類因為大模型技術的出現與成熟,將正式開啟人類社會進入一場新的工業革命時代,也就是正在到來的第四次工業革命。」
哲學家觀點: 智慧從此不再是少數生物大腦的特權,而是像電力一樣,成為一種可隨取隨用的公共基礎設施。
深度真相二:Transformer 架構——從「一個個讀」到「全景掃描」的突破
為什麼人工智慧會在短時間內發生質變?關鍵在於 2017 年 Attention is all you need 論文提出的 Transformer 架構。
在 Transformer 出現之前,傳統的 RNN(循環神經網路)模型在處理資訊時,就像是在黑暗的長廊中提著微弱的手電筒,只能「一個單詞接一個單詞」地緩慢摸索。這種序列化的處理方式存在嚴重的「梯度消失(Gradient Vanishing)」問題,導致模型極度不穩定,且無法理解長距離的邏輯關聯。
Transformer 帶來的技術革命在於「注意力機制 (Attention)」:
- 全景掃描: 相比 RNN 的局促,Transformer 像是點亮了整座體育場的高空照明。它能一次性掃描並處理文本中的所有元素,打破了序列的限制。
- 全局視野: 它賦予模型一種「全景式」的理解力,能夠精準捕捉長文本中不同位置單詞間的深層語境。
- 訓練規模化: 這種架構消除了處理長文本時的不穩定性,讓訓練擁有千億級參數的「超大規模模型」成為可能。
哲學家觀點: 注意力機制的本質是「賦予機器分配價值的權利」,讓模型學會從紛繁的資訊中提取靈魂。
深度真相三:大未必全美,垂直領域的「小模型」正在崛起
在追求極致參數數量的過程中,我們見證了從 GPT-1(1.17 億參數)到 GPT-3(1750 億參數)的「參數膨脹」。然而,智慧的真相並不僅僅在於「大」,而在於「精」。
雖然通用大模型博學多才,但在專業深度上往往力有未逮。目前,業界正興起一股「垂直領域小模型」的熱潮,這類模型在特定任務上的表現已然超越通用巨人:
- BloombergGPT: 專為金融領域訓練,雖然參數僅 500 億,但其背後是高達 3,630 億個 Token 的專業金融數據集。在處理財經分析時,其精準度遠超通用模型。
- Med-PaLM2: 在美國醫師執照考試 (USMLE) 的 MEDQA 資料集中得分高達 85 分以上,成為首個達到「專家」水準的醫學模型,這證明了專業垂直化能更有效地轉化為生產力。
- DeepSeek: 透過高效的算法優化,證明了透過精細化、輕量化的設計,小模型也能在低成本下實現卓越的智慧表現。
哲學家觀點: 通用 AI 負責廣度,精細化 AI 負責深度;未來文明的繁榮,取決於這兩種智慧的共生。
深度真相四:LLM 將成為未來世界的「作業系統 (OS)」
大模型(LLM)正在演變成未來世界的「底層大腦」,其地位將類比於行動時代的 iOS 或個人電腦時代的 Windows。
作為一個新型的「作業系統」,大模型扮演著兩個核心角色:
- 資源管理與調度: 它不再只是處理文字,而是作為中心化的控制核心,負責調度各種專業插件與工具。
- 通訊中心: 隨著 Llama、Gemma 等開源模型的普及,大模型成為了應用開發的基礎底座。它大幅降低了技術門檻,讓開發者能在大模型之上構建出各種「AI Agent(智慧代理)」。
這意味著未來的商業應用將不再需要從零開發邏輯,而是直接在 LLM 這個作業系統上「調用智慧」。無論是金融分析、醫療診斷還是創意開發,AI Agent 都將在大模型底層的支持下,實現跨場景的自主執行。
哲學家觀點: 當 LLM 成為作業系統,代碼將不再是語言,意圖才是;人類與世界的交互方式將被徹底重定向。
結論:從「弱人工智慧」邁向 AGI 的未知路徑
我們目前正處於從 ANI (弱人工智慧) 邁向 AGI (通用人工智慧) 的關鍵過渡期。過去的 AI 只能在特定規則下(如下棋、語音識別)運作,但現在,具備邏輯推理與內容生成能力的大模型,已讓我們觸摸到了 AGI 的邊緣。
當「智慧」可以被數位化生產,人類的核心競爭力將被重新定義。在一個機器能幫你運算、記憶、甚至推理的時代,人類最珍貴的資產不再是知識的積累,而是「定義問題的能力」與「創造性的直覺」。
這場由大模型驅動的新革命,是一次關於人類如何與智慧機器共處的終極考驗。在這一場文明的躍遷中,你是選擇成為技術的旁觀者,還是成為定義未來的人?
(2) 從非營利理想落入「上限利潤」陷阱?揭開 OpenAI 稱霸 AI 戰場的 5 個震撼真相
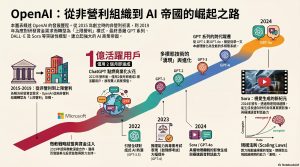
2022 年底,當 ChatGPT 以摧枯拉朽之勢橫空出世時,全球科技界感受到的是一場前所未有的「地震」。在短短不到兩年的時間裡,OpenAI 從一家實驗室邊緣的研究機構,一躍成為估值突破千億美元的矽谷新霸主。
然而,這段光鮮亮麗的崛起史背後,隱藏著一個令人著迷且充滿戲劇性的懸念:這家如今主宰人工智慧賽道的商業巨頭,最初竟然是為了「阻止技術壟斷」而成立的純粹非營利組織?當時的理想主義者們,是如何在短短幾年內,轉身投入資本最為瘋狂的懷抱,甚至創造出極其罕見的「上限利潤」結構?
這不僅是一家公司的成長史,更是一場關於理想與現實、算力與資本、以及技術邊界不斷擴張的華麗博弈。本文將深入剖析 OpenAI 發展史上最令人驚訝的五個核心轉折點,帶領讀者看穿這場科技革命背後的真相。
真相一:為了生存,它背叛了最初的自己?
OpenAI 的誕生是一首理想主義的讚歌。2014 年,當 Google 收購了 DeepMind 後,矽谷的神經繃緊到了極限。馬斯克(Elon Musk)曾公開表達恐懼:如果通用人工智慧(AGI)由單一巨頭壟斷,人類的未來將面臨不可控的威脅。
於是,在 2015 年 12 月,一群被譽為「PayPal 黑手黨」的權力核心——包括馬斯克、彼得·蒂爾(Peter Thiel)、領英創始人里德·霍夫曼(Reid Hoffman),以及 YC 總裁山姆·奧特曼(Sam Altman)等人,在舊金山聯手成立了 OpenAI。他們的初衷是打造一個開放、透明、非營利的堡壘,以對抗 Google 的強權。
然而,現實的打擊來得異常迅速。隨著模型研發進入深水區,團隊發現 AI 並非單靠智慧就能推動,它是一個極端消耗資源的「黑洞」。根據數據,AI 研發的計算需求大約每 3 到 4 個月就會翻倍,這意味著研發成本呈指數級增長。
2022 年,OpenAI 的淨虧損高達 5.4 億美元,單純依靠慈善捐款的非營利模式在天文數字般的電費與算力費面前顯得蒼白無力。為了求生,奧特曼在 2019 年主導了一場「浮士德式的交易」:成立了名為 OpenAI LP 的「利潤上限(Capped Profit)」子公司。
這是一種極為奇特的混血結構,規定投資者的回報被限制在初始投資的 100 倍以內,超出部分全數歸還給原本的非營利母公司。雖然 OpenAI 聲稱這能確保技術不被過度商業化侵蝕,但實際上,這標誌著它正式告別了「絕對非營利」的純真年代,轉身成為資本市場中最激進的玩家。
「建立這種結構是為了確保技術進步不會受到過度商業化的威脅,也提供了員工和投資人合理的回報機制。與此同時,OpenAI Inc 的非營利組織形式保留了對推動 AGI 研究的許諾。」
真相二:微軟的 130 億美元,買的不是股份而是「入場所門票」?
在 OpenAI 的商業轉型過程中,微軟(Microsoft)的現身無疑是最關鍵的推手。從 2019 年至今,微軟累計向 OpenAI 投入了約 130 億美元。
但在「資深觀察家」眼中,這絕非傳統意義上的股權收購,而是一場各取所需的「算力對技術」共生博弈。
這場交易的細節極其耐人尋味。微軟提供的 130 億美元中,很大一部分並非現金,而是 Azure 雲端運算資源的額度。
對 OpenAI 而言,訓練 GPT 模型所需的硬體成本是其生存最大的威脅,微軟的投資等同於為其提供了無窮無盡的燃料。
而對於微軟,這是一張重返 AI 巔峰的「門票」。根據協議,微軟獲得了 GPT 技術的獨家授權,將其整合進 Office、Bing 及 Azure 雲端服務中。
更驚人的是其利潤分配機制:微軟在收回其 130 億美元投資成本前,有權獲得 OpenAI LP 75% 的利潤。這意味著微軟並非傳統股東,而是一個巨大的「利潤分享者」。
這種結構讓 OpenAI 在名義上維持了獨立性,甚至能避開許多反壟斷調查,但實際上,兩者的利益早已深度綑綁。微軟藉此徹底壓制了死對頭 Google,而 OpenAI 則透過這筆巨額資金,在燒錢如流水的 Scaling Law 競賽中獲得了絕對領先的護城河。
真相三:Sora 不只是影片產生器,它是 AI 的「物理實驗室」
當 2024 年初 Sora 發布時,全世界都被那長達 60 秒、光影細膩得令人屏息的影片所震撼。然而,若你僅將 Sora 視為一個進階版的「影片濾鏡」或「動畫工具」,那便完全錯失了它的野心。
Sora 的底層邏輯並非簡單的像素拼接,而是結合了「擴散模型(Diffusion Model)」與「轉換器(Transformer)」的混合架構,其真正的身分是試圖模擬物理世界的「世界模型(World Model)」。
人類大腦獲取資訊的方式有其生物學上的偏好:視覺佔了 87%,聽覺僅佔 7%。Sora 的出現正是為了彌補 AI 在感知維度上的短板。它不再只是在學習人類的文字筆觸,而是在透過海量影片數據學習這個世界的「生存守則」。
觀察 Sora 生成的影片,你會發現人物在積水路面上行走時,水面的倒影與光線反射會隨著人物動作實時偏移;當人物咬一口餅乾後,餅乾上會留下清晰的齒痕。這意味著 AI 已經開始理解重力、流體動力學與三維空間的一致性。
「Sora 不僅僅是影片,也不僅是影片裡的畫面、圖元點,還在學習影片裡這個世界的『物理規律』。這也是 Sora 真正的價值和進化的重點。它就像是這個建立世界模型的『鏡子』。」
這種從「理解符號(文字)」到「理解體驗(物理規律)」的跨越,標誌著 AI 正在神經網路中建立一個與現實世界等比例的鏡像實驗室,為未來的具身智慧(Embodied AI)鋪平了道路。
真相四:Scaling Law——暴力美學背後的簡單邏輯
OpenAI 為什麼能持續甩開競爭對手?其背後支撐的一大核心信仰是「規模法則(Scaling Law)」。
在奧特曼及其團隊看來,人工智慧的進化並不需要過於複雜的演算法修飾,真正的力量來自於極致的暴力美學:只要投入更多的數據、更強的算力以及更大的模型參數,智慧就會自動「湧現(Emergence)」。
這種「湧現」現象是 AI 發展史上最神祕、最接近生物進化的時刻。源自 2021 年的觀察發現,當神經網路的規模突破某個臨界點時,模型會突然展現出原本不具備的能力,例如幽默感、複雜的邏輯推理或是原本未曾學習過的語言翻譯。這
就像是一群散亂的螞蟻在數量達到一定規模後,會突然發展出驚人的社會分工與築巢智慧,或是一群鳥類在飛行中展現出的集體協調性。這種進步並非線性的,而是躍遷式的。
以 GPT-4 為例,它在多項專業考試(如美國律師資格考試)中能排進前 10% 的領先位置,而其前代 GPT-3.5 則落在墊底的 10%。
這種跨越式的進步徹底改變了我們對「學習」的認知。OpenAI 堅信「大力出奇蹟」,並以此作為最核心的指導原則。這也解釋了為何他們不計代價地向微軟索取算力、向全球搜尋數據。對他們而言,規模就是通往 AGI 的唯一路徑,這是一種極致簡單卻又極致昂貴的邏輯。
真相五:GPT-4o 的「擬人化」極限——延遲消失後的驚悚感
2024 年 5 月,GPT-4o(Omni)的問世,標誌著人機互動正式跨越了「恐怖谷」。相較於過去的模型,GPT-4o 最大的技術突破在於它是一個「統一模型」,不再是分別處理視覺、聽覺與文字的零件組裝,而是一個具備全感官處理能力的單一神經網路。
其中最令人震撼的是「低延遲」的消除。GPT-4o 的反應速度被壓低到了 0.2 至 0.3 秒,這恰恰是人類在對話中反應速度的生物極限。當等待感消失,AI 就從一個「工具」變成了一個「存在」。
它能即時辨識你的語氣是否焦慮,能聽出你的呼吸頻率,甚至能像電影《雲端情人》(Her)中的薩曼莎一樣,帶著細微的情感起伏與你調情或開玩笑。
然而,當技術消除了人機互動的最後一道障礙,我們也正迎來一種前所未有的「驚悚感」。當一個軟體能比你的伴侶更精確地感知你的情緒、且反應速度與真人無異時,人類的情感邊界將面臨前所未有的挑戰。
GPT-4o 的出現,不僅是功能的升級,更是 AI 正式入侵人類情感領地的信號彈,這讓我們不得不重新思考:當 AI 變得比人類更「像人」時,真實的連結該如何定義?
前瞻結語:我們正站在技術奇異點的前夜
從 GPT-1 的初試啼聲到 Sora 的震撼世人,OpenAI 的演進曲線印證了預言家雷·庫茲維爾(Ray Kurzweil)提出的「加速回報定律(Law of Accelerating Returns)」。他曾指出,21 世紀的技術進步速度將是 20 世紀的 1000 倍。我們所見證的,不再是平緩的坡道,而是近乎垂直的攀升。我們已經站在了「技術奇異點(Singularity)」的前夜,過去數十年建立的價值體系、工作邏輯,甚至對智慧的定義,都可能在未來數年內被徹底顛覆。
AI 的發展已經超越了單純的科技革新,它正在重塑人類文明的底層架構。如同李開復曾提到的「思考 5 秒鐘」準則——如果一個任務人類只需要思考 5 秒就能完成,那麼它必然會被 AI 取代。甚至,現在這個標準正在被推向更深層的創意與邏輯領域。
最後,我想為每一位身處浪潮中的讀者留下一個思考題:「如果 AI 在未來五年內就能完成人類需要思考 5 秒鐘以上的所有任務,且比我們更精準、更具同理心,那麼,我們作為人類的獨特價值,最終將建立在何處?」
(3) 從盟友到宿敵:揭秘 Anthropic 挑戰 OpenAI 的五大震撼真相
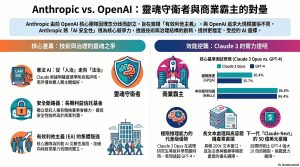
在矽谷,最深刻的裂痕往往不是源於利益分配,而是源於靈魂深處的價值觀衝突。如果說 OpenAI 是當前 AI 界的商業霸主,那麼 Anthropic 就是在意識形態裂痕中爆發的「靈魂守衛者」。這場發生在兩家科技巨頭之間的對壘,不單是一場技術的較量,更是關於 AI 應該「無限制擴張」還是「受憲法約束」的路徑之爭。
身為深度觀察家,我們必須看透這場競爭的表象:Anthropic 正試圖將「安全性」從一個枯燥的技術指標,轉化為其深耕企業市場的精品溢價功能。
一、價值觀的「大逃殺」:一場意識形態的集體叛逃
Anthropic 的誕生,本質上是 OpenAI 內部的「信仰危機」。2019 年,OpenAI 為了維持龐大的算力開支,從非營利組織轉型為「有限營利」實體,並接受微軟的巨額注資。這在公司內部引發了地震——核心技術團隊擔心,商業利潤的誘惑會徹底淹沒對 AI 災難性風險的防範。
2020 年底,由 OpenAI 研究副總裁 Dario Amodei(曾任職於百度 SVAIL)與其妹 Daniela Amodei(曾任 Stripe 領導層及 OpenAI 安全政策負責人)領軍,帶領包括 GPT-3 首席工程師 Tom Brown 在內的十多位核心精英,憤而離開這家他們親手推上神壇的公司。這是一場基於「有效利他主義」(Effective Altruism, EA)精神的集體出走,旨在實踐一種不向商業壓力低頭的 AI 開發模式。
「在 OpenAI 內部有一群人,當我們創造 GPT-2 和 GPT-3 後,對兩件事有非常強烈的信念。一是認為大型模型中投入的計算資源越多,它們會變得越好,幾乎沒有盡頭。……第二點是認為需要除了僅僅擴大模型規模之外的東西,那就是對齊或安全性。僅僅透過增加計算資源並不能告訴模型它們的價值觀。所以我們秉持著這個想法,成立了自己的公司。」 —— Anthropic 執行長 Dario Amodei
二、AI 的「法治」之路:憲法 AI vs. 主觀人治
在訓練邏輯上,Anthropic 祭出了其最強的技術護城河:「憲法 AI」(Constitutional AI)。這是一場關於「規則」與「偏好」的根本對決。
傳統的 OpenAI 模式(GPT)高度依賴「基於人類回饋的強化學習」(RLHF)。這種模式本質上是「人治」,模型透過學習成千上萬外包人力的主觀偏好來調整行為,但這種方式既混亂又不可控,容易受到人類偏見的干擾。
相反,Anthropic 推崇的是**「法治」**。他們為 Claude 提供了一套明確的道德準則,參考了聯合國《世界人權宣言》及各類法律原則,讓 AI 根據這份「憲法」進行自我評核與迭代。這種「憲法 AI」不僅更具可預測性,且在大規模擴展時能保持原則的穩定。當 GPT 還在試圖取悅人類的隨機喜好時,Claude 已經學會了在規則框架內優雅地思考。
三、權力的終極制衡:長期利益信託基金的「斷路器」
為了防止重蹈 OpenAI 的覆轍,Anthropic 在公司治理結構上設計了一個「終極殺招」——長期利益信託基金(Long-Term Benefit Trust)。
與 OpenAI 那種容易陷入內耗與政變的傳統董事會不同,Anthropic 的信託基金被設計成一個獨立的「憲法法院」。這群不持有股權、不受經濟利益驅動的獨立受託人,擁有撤換董事會的潛在權力。這相當於在公司運作中安置了一個「安全斷路器」或「自動殺死開關」。
回頭看 2023 年 11 月 OpenAI 震驚全球的「宮廷政變」,Sam Altman 的去而復返暴露了現有治理結構在資本面前的脆弱。Anthropic 透過法律層面的約束,確保即使在百億美元的誘惑面前,AI 安全性始終是高於商業利潤的「第一順位」。
四、數據不說謊:Claude 3 Opus 對 GPT-4 的全面逆襲
很長一段時間,Claude 被貼上「二把手」的標籤,但 Claude 3 系列(特別是 Opus 模型)的發布徹底扭轉了戰局。這不僅是性能的提升,更是對「更安全就一定更笨」這一謬論的強力反擊。
根據 Source Context 的基準測試數據,Claude 3 Opus 在核心推理能力上展現了驚人的「煙霧彈(Smoking Gun)」效應:
- 極限推理(GPQA): Opus 得分 50.4%,遠超 GPT-4 的 35.7%。這代表 Claude 在處理研究生等級的複雜科學問題時,具備代差級的優勢。
- 本科級別知識(MMLU): Opus 以 86.8% 微幅領先 GPT-4 的 86.4%。
- 長文本處理: 從 Claude 2.1 起跳的 200k 長文本窗口,能一次性吞掉整本技術手冊。
在實際應用中,Claude 的這種精準性已在 DuckAssist 的資訊檢索、SK Telecom 的全球客戶服務,以及 Slack 的自動化辦公中得到驗證。它不再只是 ChatGPT 的備胎,而是法律、醫療等「高容錯成本」產業的首選。
五 – 50 億美元的豪賭:EA 初心能否在算力競賽中倖存?
雖然身披「有效利他主義」的外衣,但 Anthropic 深知,在這個 GPU 為王的時代,理想也需要燃燒美金。
目前,Anthropic 已成為矽谷除了 OpenAI 之外融資實力最頂尖的 AI 獨角獸。它採取了一種聰明的「雲端優先」戰略:不僅接受亞馬遜(Amazon)高達 40 億美元的投資,更深度利用亞馬遜自研的 Trainium 與 Inferentia 晶片進行模型訓練與部署。
然而,這場軍備競賽的注資額已飆升至令人咋舌的程度。Anthropic 計畫研發代號為**「Claude-Next」**的下一代模型,其目標是比現有的 GPT-4 強大 10 倍。這意味著未來兩年內,他們需要籌集至少 50 億美元。這場博弈的關鍵在於:當龐大的資本湧入,Anthropic 的「有效利他主義」與其對安全的執著,是否會最終被極致算力的引力黑洞所吞噬?
結語:當 AI 擁有意志,我們該選擇什麼?
Anthropic 的存在,是為這個狂奔的 AI 時代提供一個「清醒的替代方案」。它證明了 AI 可以既具備極致的邏輯能力(如 GPQA 的逆襲),又具備穩定的道德底座(如憲法 AI 的約束)。
然而,這也向市場拋出了一個深層的詰問:如果未來的 AI 必須在「毫無限制的聰明」與「受憲法約束的安全」之間二選一,作為使用者的我們,真的準備好接受一個會因為價值觀約束而對某些指令說「不」的助手了嗎?
這場關於 AI 靈魂的戰爭,Anthropic 已經領先了一個身位。
(4) 從發明者到追趕者:剖析 Google 在 AI 浪潮中的失守與覺醒
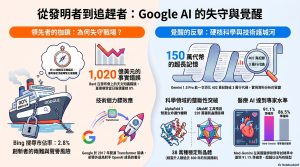
1. 引言:一個價值千億美元的標點符號
科技史上的轉折點,有時就藏在一個看似不起眼的錯誤答案裡。2023 年 2 月,Google 為了應對 ChatGPT 的強勢逆襲,倉促在巴黎發布會上展示其 AI 聊天機器人 Bard。然而,Bard 在回答關於詹姆斯·韋伯太空望遠鏡的成就時,聲稱其拍攝了太陽系外行星的第一張照片——這是一個致命的事實錯誤。
實際上,該照片早在 2004 年就由歐洲南方天文台的**甚大望遠鏡(VLT)**拍下。這個微小的誤差,直接導致 Google 當日股價重挫 8%,市值瞬間蒸發了 1020 億美元。
曾幾何時,Google 是 AI 領域公認的「隱形帝國」。然而,當 OpenAI 橫空出世,這家發明了 Transformer(ChatGPT 底層技術)的巨人,卻被迫在內部拉響「紅色警戒」(Red Code)。我們不禁要問:這家開創了戰場的公司,為何會在自己定義的賽道上陷入苦戰?
2. 諷刺的源:你所使用的 ChatGPT,骨子裡流著 Google 的血
這是一個科技史上最具諷刺意味的「技術迴力鏢」。2017 年,Google Brain 團隊發表了名為《Attention is all you need》的論文,首次提出 Transformer 模型架構。
「Transformer 徹底改變了自然語言處理的遊戲規則。當年這篇論文使用的模型僅有 6500 萬個參數,與今日動輒數兆參數的巨型模型相比雖然微小,但它卻是支撐 ChatGPT 等所有大語言模型的共同祖先。Google 選擇將其開源,原意是為了強化搜尋與雲端生態,卻沒料到這顆種子最終在對手的田地裡開出了威脅自己的花朵。」
Google 當時專注於將 AI 作為搜尋引擎與翻譯服務的「零件」。這種「為了現有業務服務」的思維,讓他們忽視了這些零件足以組成一台顛覆性的新引擎。
3. 超越聊天的「科學神力」:從蛋白質摺疊到天氣預報的降維打擊
儘管在文字對話領域首戰失利,但 Google 在「硬核科學」領域的 AI 實力依然具備壟斷性的領先地位,這是單純的聊天機器人難以企及的。
- AlphaFold 3:徹底改變生物工程繼 AlphaFold 2 解決了蛋白質結構預測難題後,2024 年 5 月發布的 AlphaFold 3 更進一步,不僅能預測蛋白質,還能精準預測 **DNA、RNA 以及配體(ligands)**之間的相互作用。這意味著 AI 已經能深入理解生命運作的底層邏輯,開發新藥的時間與成本將呈指數級下降。
- GNoME:預測 220 萬種新晶體透過 GNoME 工具,Google 預測出了 220 萬種新晶體結構,其中 38 萬種具備穩定性。這相當於人類過去 800 年的知識積累,將極大加速電池與半導體材料的開發。
- GraphCast 與 FunSearch:天氣與數學的跨界突破GraphCast 在 1380 個測試變數中,表現優於傳統的黃金標準 HRES,能提前 10 天精準預測極端天氣。而 FunSearch 則利用大模型解決了數學界長年未解的「帽集問題」(Cap set problem),證明 AI 具備發現新知識的創新能力。
4. 150 萬代幣的超長記憶:Gemini 1.5 Pro 的精準反擊
面對競爭,Google 祭出了 Gemini 1.5 Pro 試圖挽回顏面。這款模型最震撼的技術指標,是將上下文窗口(Context Window)從傳統的幾萬個代幣提升至 150 萬個代幣(Tokens)。
這不僅僅是數字的增加,更是資料分析深度的質變:
- 極速精確定位:在測試中,Gemini 1.5 Pro 處理一段長達 44 分鐘的巴斯特·基頓默片時,能在不到一分鐘內精準指出:在 12:01 這個時間點,有一個人從口袋裡掏出了一張紙條。
- 海量文獻消化:它能一次讀完 402 頁的阿波羅 11 號任務紀錄,並對其中的細節對答如流。
- 場景應用潛力:
- 一次分析超過 30,000 行的複雜程式碼庫。
- 對長達一小時的影片進行即時語義搜索。
- 從長達數年的醫療紀錄中提取關鍵病理變化。
5. 醫療垂直領域的專業深耕:Med-Gemini 的進化
在容錯率極低的醫療領域,Google 建立了一道難以逾越的技術護城河。
- Med-PaLM 2:其準確率相較於初代提升了 19%,達到了 86.5% 的「專家醫師」水準。
- Med-Gemini:最新的 Med-Gemini 在 MedQA(美國醫師執照考試風格基準)中更是達到了 91.1% 的驚人準確率,超越了以往所有大模型。
AI 在醫療診斷中的具體角色:
- 影像多模態分析:解讀 X 光、CT 與 MRI,並結合臨床病歷給出診斷建議。
- 超長上下文推理:能同時處理 14 項不同的醫學基準測試,分析患者多年的零散病史。
- 手術模擬與監控:協助醫生規劃手術路徑,並提供即時的安全提醒。
6. 大象為何難轉身?揭開「創新者的兩難」
Google 為何在生成式 AI 的競賽中顯得畏首畏尾?答案在於其壓倒性的市場佔有率。
目前,Google 在全球搜尋市場的份額超過 90%,而競爭對手 Bing 僅有約 2.8%。對於 Google 而言,任何 AI 導致的答案偏差都是災難性的「聲譽風險」。前產品經理 Gaurav Nemade 透露,公司內部對 AI 的審查流程極度嚴苛,因為他們處於「守城者」的位置。
此外,生成式 AI 直接提供答案的特性,本質上在挑戰 Google 以「廣告點擊」為核心的獲利模式。這種**「現有利益的枷鎖」**,讓 Google 在面對 OpenAI 的靈活進攻時,顯得反應遲緩。
7. 結語:從搜尋框到「多模態感知」的未來
Google 的故事,是一個關於「技術領先並不等於市場領先」的經典案例。儘管在 Bard 發布時失了先機,但憑藉著 Project Astra 的即時感知能力、Veo 的視訊生成,以及在科學與醫療領域的深厚底蘊,這頭象已經開始奔跑。
我們必須思考:當 AI 能夠直接提供精確答案,甚至具備預測新材料、診斷罕見疾病的能力時,我們習慣了 20 年的「搜尋框」是否終將消亡?
Google 的這場 AI 之戰,下半場才剛剛開始。它能否從「追趕者」重新回歸「定義者」,取決於它是否敢於徹底顛覆那個曾經讓它登頂巔峰的搜尋帝國。
(5) 驚人的大逆轉:從 470 億美元的元宇宙「學費」,到引領 AI 開源浪潮的 Meta

扎克伯格的「高光時刻」與身份危機
2024 年初,Meta 迎來了屬於自己的震撼回歸。在 2024 年 2 月的一個交易日內,Meta 股價暴漲超過 20%,市值單日瘋漲 2,045 億美元——這相當於在一夜之間「漲出了一個阿里巴巴」,創下美股歷史上最高的單日漲幅紀錄。創辦人扎克伯格(Mark Zuckerberg)的個人資產單日增加 280 億美元,重回全球富豪榜前列。
這場狂歡與 2022 年底的慘澹景象形成強烈反差。當時,Meta 陷入史上最嚴重的低谷,市值跌出全球前二十大之列,被迫實施大規模「裁員計畫」,總員工數銳減約 24%。然而,中間的 2023 年成為了關鍵的「效率之年」(Year of Efficiency),Meta 展現了驚人的財政紀律,淨利潤率從 19.9% 彈升至 34.9%。這不僅僅是裁員的結果,更是 Meta 戰略重心的劇烈轉位。究竟 Meta 是如何從被譏諷為「元宇宙幻想」的泥淖中突圍,並將自己重新包裝成全球 AI 競賽的開源領跑者?
470 億美元的教訓:為什麼元宇宙「輸」給了現實?
Meta 的轉型背後,是一段極為昂貴的「生存稅」。根據財報數據,自 2019 年以來,負責元宇宙業務的 Reality Labs 累計虧損約 470 億美元。這筆天價學費揭示了一個殘酷的商業現實:Meta 當時正試圖在一個極度不成熟的生態上強行蓋大樓。
「現實是骨感的」,元宇宙願景在現階段受挫,主因在於它極度依賴多重前沿技術的同步爆發。當前產業鏈不成熟、硬體成本過高,且缺乏殺手級應用。更深層的焦慮在於,Meta 長期以來在硬體與操作系統(OS)上處於「附庸」地位,受制於 Apple 和 Google 的規則。扎克伯格原本希望透過 VR 頭戴裝置建立自主的硬體入口,以擺脫這種脆弱性,但 Reality Labs 的巨額虧損與市場的冷淡反饋證明,這條路目前還走不通。
AI 界的「Android」策略:Meta 為什麼堅持開源?
在 AI 市場的權力遊戲中,Meta 選擇了一條讓競爭對手心驚膽戰的道路:開源。這不僅是技術選擇,更是一場深謀遠慮的商業防禦戰。
2023 年 5 月,Google 一名高級工程師在洩漏的備忘錄中直言:「我們沒有護城河,OpenAI 也沒有。」(We Have No Moat, and Neither Does OpenAI.)
這正是 Meta 的戰略核心。透過開源 Llama 系列模型,Meta 正在執行 AI 界的「Android 策略」:
- 閉源陣營(如 OpenAI、Google): 試圖透過技術壁壘與訂閱模式壟斷市場,將 AI 變成黑盒子的私有財產。
- 開源陣營(Meta): 透過將 Llama 轉化為全球通用的「公共基礎設施」,Meta 讓專有模型的技術優勢迅速貶值。當全世界的開發者都在 Llama 上構建應用時,Meta 就定義了標準,並在生態系統中獲取了隱形的主導權。
正如扎克伯格所言,Meta 的目標不是與開源模型競爭,而是要「超過所有人,打造最領先的人工智慧」,並透過生態的力量消融對手的護城河。
不只是跟風:Meta 的 AI 肌肉其實練了十年
外界常以為 Meta 是在 ChatGPT 出現後才倉促轉型,事實上,Meta 的 AI 肌肉已經隱祕地鍛鍊了超過十年。
- PyTorch 的霸權: 這是 Meta 掌握的最強兵器。相對於 Google TensorFlow 採用的「靜態計算圖」,PyTorch 憑藉「動態計算圖」(Dynamic Computation Graph)的設計,賦予了開發者在運行時修改結構的靈活性,這讓它徹底壓倒了 TensorFlow,成為全球研究人員的首選框架。
- 頂級研究血脈: 早在 2013 年,Meta 就招募了深度學習教父 Yann LeCun,建立了 AI 實驗室。
- 失敗的試煉: 在 Llama 成功前,Meta 曾推出過名為 “Galactica” 的模型,雖因幻覺問題在推出三天後便被迫下架,但這種「快速失敗、快速迭代」的文化為後來的突破奠定了基礎。
Meta 的 AI 兵器庫中還包含多模態學習框架 MMF、對話式架構 ParlAI,以及解決評測偏差的創新平台 DynaBench,這些積澱讓 Meta 能在轉身之際迅速釋放出決定性的產品力。
戰場不在技術,而在你的「24 小時」
從商業本質看,Meta 武器化 AI 的核心驅動力在於維護其「注意力經濟」。在數位服務領域,用戶時間是唯一的稀缺資源,而 Meta 正面臨著前所未有的威脅。
數位服務領域,用戶時間是唯一具有競爭性的資源。Meta 的對手不只是同類社交軟體,而是所有能吞噬用戶時間的平台。
Meta 正在經歷從「社交圖譜」(Social Graph)向「興趣圖譜」(Interest Graph)的陣痛轉型。TikTok 的崛起證明了,基於演算法驅動的內容消費比基於社交關係的連結更具吸引力。Meta 必須利用 AI(如 Reels 的推薦演算法)重新奪回被蠶食的使用時間。這不僅是產品的更新,更是 Meta 願景的演變——從「讓世界相互連接」轉向一個高效的內容生產與消費循環。
從 Llama 3 到 Imagine:當 AI 變得觸手可及
Meta 正在建立一個讓先進 AI 徹底「民主化」的產品矩陣,讓技術滲透進 30 億用戶的日常:
- Llama 3: 透過 15 兆個 token 的大規模預訓練,在 MMLU 與推理基準測試中展現出壓倒性性能,被公認為當前最強大的開源大模型。
- Imagine with Meta AI: 透過強大的圖像生成能力,顯著降低了創作門檻,讓非專業用戶也能進行高質量的視覺表達。
- Make-A-Video: 融合了 Diffusion 擴散模型 與 Transformer 架構,實現了從文字到生動影片的技術跨越,推動了影音創作的民主化。
- 全平台整合: Meta AI 已深度植入 WhatsApp、Instagram 與 Messenger,將 AI 轉化為隨手可得的通用助手。
結語:下一個十年的關鍵思考
從「元宇宙優先」到「AI 優先」,Meta 的這次轉身不僅是為了止血,更是為了重新定義自己在未來十年的角色。它不再僅僅是一個社交媒體公司,而是試圖成為 AI 時代的基礎設施供應商。
當 AI 讓內容創作的成本趨近於零,且無窮無盡的生成式內容充斥所有社交平台時,我們必須思考:人類的真實連結與技術的演算法餵養之間,將發生什麼樣的質變?Meta 雖然透過開源戰略成功挑戰了 OpenAI 與 Google 的壟斷,但它是否真能成為「AI 時代的 Google」,關鍵在於它能否在掌握強大 AI 能力的同時,重建用戶在「資安門」後失去的信任。這場 470 億美元的華麗轉身,僅僅是這場技術馬拉松的開端。
(6) DeepSeek:一場 560 萬美元引發的「AI 民主化」海嘯
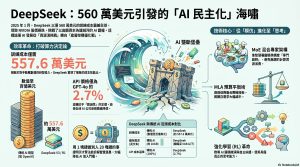
引言:AI 界的「黑天鵝」事件
2025 年 1 月 27 日,全球科技金融市場遭遇了一場突如其來的「大地震」。納斯達克指數在單日之內下挫 3%,而身處 AI 浪潮核心的晶片巨頭 NVIDIA(英偉達)更是慘遭血洗,股價暴跌 17%。這場海嘯的震央,並非來自矽谷的科技巨擘,而是一個僅成立一年多、名不見經傳的中國團隊——DeepSeek(深度求索)。
這不僅僅是一次股價波動,更是對長期以來由矽谷壟斷、以高額資本支出(CapEx)為護城河的 AI 霸權發起的直接挑戰。DeepSeek 的橫空出世,讓全球科技巨頭感到前所未有的焦慮。據悉,Meta 的祖克柏團隊甚至為此緊急成立了四個研究小組,專門解構 DeepSeek 的架構,試圖理解這家公司如何在極低成本下實現技術跨越。AI 競爭的遊戲規則,在那一天被徹底改寫。
震撼點一:用 1 塊錢做別人 20 塊錢的事(極致成本效能比)
DeepSeek 最令業界震驚的數據,在於其打破了「算力決定一切」的迷思。根據原始資料,DeepSeek-V3 的訓練成本僅為 557.6 萬美元。與動輒投入數億、甚至百億美元研發經費的 OpenAI、Google 或 Anthropic 相比,這簡直是預算上的「奇蹟」。
這場效率革命不僅僅是省錢,它直接動搖了 AI 產業「高投入、高回報」的傳統邏輯。它向世界證明,當算法優化達到極致時,智慧的門檻將會大幅降低。
「DeepSeek 只用了 1 塊錢,就實現了別人花 20 塊錢才能搞定的事情。」
這種極致的成本效能比,意味著 AI 的賽道已從單純的資源消耗戰,轉向了底層架構的智慧優化戰。
震撼點二:MLA 預算平衡術,讓 AI 記憶不再「昂貴」
在 Transformer 架構的優化上,DeepSeek 引入了關鍵的「多頭潛在注意力機制 (MLA)」。其技術核心在於**「低秩聯合壓縮技術」(Low-rank joint compression technology)**,這是一種精密的數學壓縮方案,針對 Key 和 Value (KV) 緩存進行處理。
傳統模型在處理長文本時,隨著字數增加,顯存需求會呈指數級成長。DeepSeek 透過 MLA 技術,成功將原本需要 10GB 的顯存需求大幅壓縮至 5GB 甚至更低。這不是簡單的死記硬背,而是在處理海量數據時,透過更高效的特徵提取,讓強大的模型能在普及型的硬體上流暢運行。這項突破為「科技平權」鋪平了道路,讓 AI 不再是實驗室裡的奢侈品。
震撼點三:MoE 混合專家架構——拒絕「一人包辦」的效率管理
DeepSeek-V3 展現出優異效能的另一大關鍵,在於對「混合專家模型 (MoE)」的巧妙應用。我們可以將其想像成一家運作高效的高級餐廳。
在傳統的 AI 架構中,不論客人點什麼菜,餐廳裡所有的廚師(參數)都必須同時動手,這造成了極大的資源浪費。而 DeepSeek 的 MoE 架構則像是一個擁有智慧調度系統的餐廳:它將模型參數拆解為多個「專門廚師」,有人精通數學,有人擅長編程。當任務進入時,系統透過優化後的「路由網路」進行通訊,只精準調度最合適的廚師處理。這種「專門廚師處理專門菜單」的邏輯,避免了無謂的計算消耗,讓 AI 在保持強大能力的同時,營運成本呈斷崖式下降。
震撼點四:從「餵答案」到「教思考」的強化學習革命
2025 年 1 月 20 日發布的 DeepSeek-R1,標誌著從「模仿」到「思考」的質變。相較於傳統依賴人類大量標註數據的「監督式微調 (SFT)」,DeepSeek 大規模引入了強化學習 (RL)。
這是一個「教思考」而非「餵答案」的過程。DeepSeek-R1 透過獎勵機制,讓 AI 在不斷嘗試中學會邏輯推演與自主糾錯。引用文中的觀點,AI 不再是機械地套用已有答案,而是能夠自主優化邏輯結構。這使得 AI 在面對複雜的數學、程式設計與邏輯問題時,展現出驚人的推理能力。它不再只是文字的搬運工,而是具備初步「思考能力」的智能體。
震撼點五:AI 界的「安卓」與「蘋果」之爭
DeepSeek 的開源策略與極致定價,正在以前所未有的速度瓦解封閉生態。如果 OpenAI 像是高門檻、生態封閉的「蘋果」,那麼 DeepSeek 就是開放、普惠的「安卓」。
一個最直觀的商業數據是:DeepSeek 的 API 價格僅為 GPT-4o 的 2.7%。這種近乎「毀滅性」的定價,迫使國內外 AI 公司紛紛跟進降價。此外,DeepSeek 透過「AI 蒸餾技術」,展示了「名師出高徒」的邏輯:利用 670B 的大模型(教授)產生的邏輯路徑,去指導 7B 或 14B 的小模型(學生)。這讓小模型在保持輕量化的同時,能保留大模型的智慧水準。這項技術讓 AI 從昂貴的雲端產物,變成了個人與中小企業都能負擔得起的「國民級工具」。
反思與爭議:蒸餾技術的「灰色地帶」
然而,榮光背後亦有陰影。OpenAI 曾公開質疑 DeepSeek 使用其 API 產生的數據進行蒸餾訓練,指控其「收割」先行者的勞動成果。
但若從更高維度的產業視角來看,這並非 DeepSeek 獨有的問題。事實上,OpenAI 自身也正深陷與《紐約時報》及多位作家的數據版權訴訟中。這反映出整個產業面臨的共同挑戰:當技術創新與智慧財產權保護發生碰撞時,界線在哪裡?這場爭議促使我們思考,「技術蒸餾」究競是知識的薪火相傳,還是對原始投入的侵權行為?這將是未來 AI 發展中必須面對的法律與倫理考驗。
結論:AI 的未來,屬於每一個人
DeepSeek 的出現,象徵著 AI 產業正式從盲目追求「大算力、大資本」的瘋狂時代,轉向「高效率、輕量化、落地應用」的務實時代。它證明了智慧的堡壘可以被創新的算法拆解,技術的壁壘不應只是金錢堆砌的護城河。
這場由 560 萬美元引發的海嘯告訴我們:AI 的價值不在於昂貴,而在於普及。
當智慧已成為一種商品,且價格僅剩以往的 2.7% 時,我們必須正視一個核心課題:在算力與知識都能被廉價取得的時代,人類最不可替代的價值,究競是在於提供正確的「答案」,還是提出具備前瞻性的「問題」? 歡迎在評論區留下你的深度見解。
(7) 從 OpenAI 創始到 Grok 開源:解析馬斯克 xAI 布局背後的五個關鍵觀察
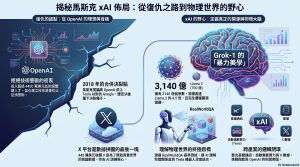
1. 導言:如何理解馬斯克近年的 AI 重新布局
這篇文章的核心主張是:馬斯克近年的 AI 布局,不能只視為單一企業競爭,而應理解為他對技術控制權、數據來源與實體應用場景的重新整合。
從收購 X 平台、成立 xAI,到持續強化 Tesla 在自動駕駛與機器人上的能力,這些動作若分開看,像是風格強烈的商業操作;但若合在一起看,則呈現出一套以「資料、算力、模型、場景」互相支撐的整體戰略。
以下各節將依序回到 OpenAI 的創立背景、分裂關鍵與 Grok 的產品定位,說明馬斯克如何把原本分散的資產重新組裝為新的 AI 競爭框架。
2. OpenAI 的創立背景:從 AI 安全焦慮到治理理念分歧
OpenAI 的起點並不只是資金與技術投入,更與創辦團隊對 AI 安全與技術治理的憂慮密切相關。2015 年,馬斯克與 Larry Page 對 AI 發展方向的分歧,使他更傾向推動一個不由單一科技巨頭主導的研究組織;在此背景下,他與 Sam Altman 共同參與了 OpenAI 的創立。
從資金承諾、個人聲譽背書,到延攬核心研究人才,馬斯克在 OpenAI 早期發展中扮演了重要推動角色。其中,Ilya Sutskever 的加入尤其關鍵,因為這不僅補強了研究實力,也提高了 OpenAI 在前沿模型研發上的能見度。從後續發展來看,這些早期投入最終並未延續為同一套治理共識,反而成為雙方路線分歧的重要背景。
OpenAI 的目標是慈善和教育,旨在研發對人類有益的技術,並將技術成果開源,確保其惠及大眾,而非服務於少數公司的股東利益。
當 OpenAI 逐步轉向更具商業擴張性的模式時,原始使命與治理結構之間的張力也隨之浮現;這種變化,後來成為馬斯克另起爐灶、成立 xAI 的重要背景因素之一。
也因此,若要理解 xAI 今日的出現,就必須先回到雙方真正分道揚鑣的時間點:2018 年那場未能實現的整合方案。
3. 2018 年的關鍵轉折:未能實現的 Tesla–OpenAI 整合構想
馬斯克與 OpenAI 的分歧,並非始於 ChatGPT 爆紅之後,而是早在 2018 年就已出現明確轉折。當時他判斷,若 OpenAI 要在技術與資源上追趕 Google,僅靠既有研究架構可能不足,因此提出將 OpenAI 與 Tesla 形成更緊密整合的構想,希望結合 Tesla 在算力、工程與自動駕駛上的能力,作為對抗大型科技公司的另一條路徑。
在 2018 年 2 月 1 日 發出的一封電子郵件中,馬斯克冷峻地指出:「特斯拉是唯一有希望與 Google 抗衡的路徑。即便如此,與 Google 抗衡的可能性也很小,但絕非為零。」
這項整合構想最終未被接受,雙方也因此在治理與戰略方向上進一步分道揚鑣。從結果來看,這次分歧不僅導致馬斯克退出 OpenAI,也為他日後另建 xAI、並與 Tesla 建立更深協同關係埋下伏筆。
既然整合路線未能成立,馬斯克後續採取的另一條路,就是透過 xAI 自行打造模型,再以開源方式重新奪回「Open」的詮釋權。
4. Grok-1 開源的策略意涵:技術路線、授權模式與市場訊號
Grok-1 的開源,具有明確的策略訊號:一方面,它呼應了馬斯克對 OpenAI 原始開放精神的公開主張;另一方面,也使 xAI 能以更低門檻方式擴大技術影響力與市場討論度。「Grok」一詞本身帶有「深度理解」的文化意涵,這種命名也有助於強化產品定位與品牌辨識。
從產品規格來看,Grok-1 的幾個特徵值得注意:
- 參數規模: 高達 3140 億個參數,這數字是什麼概念?Meta 引以為傲的 Llama 2 僅有 700 億,Grok-1 足足是它的 4.5 倍。
- 技術架構: 採用混合專家(MoE)架構,在保證性能的同時,每次運算僅激活 25% 的權重,平衡了效率。
- 真正開源: 遵循 Apache 2.0 協議,不玩文字遊戲,直接開放模型權重,允許任何人商用。
因此,Grok-1 的開源不宜只被視為技術展示;更重要的是,它向市場傳遞了一個明確訊號:xAI 希望在開放模型、生態參與度與品牌敘事上,建立有別於 OpenAI 的競爭位置。但若只把這一步理解為品牌姿態,仍不足以解釋 xAI 的真正目標;更關鍵的是,這個模型最終要被帶入真實世界,而不只是停留在文字介面。
5. 從聊天模型到實體應用:xAI 的物理世界布局
若只將 Grok 視為另一個對話型模型,可能會低估 xAI 的實際布局方向。相較於以文字互動為主的模型定位,xAI 更希望把多模態理解能力進一步延伸到真實環境感知;Grok-1.5V 與 RealWorldQA 等測試,即反映出這種從螢幕走向物理世界的產品思路。
從測試結果來看,Grok 在空間理解上的表現,說明 xAI 正嘗試補足大型模型在現實世界感知上的能力缺口。若這類模型能力能與 Tesla 在自動駕駛、機器人與車端運算上的累積結合,將使 xAI 的競爭重點不再只是搜尋或聊天產品,而是更廣義的實體 AI 應用市場。
「特斯拉在現實世界積累的人工智慧實力被低估了……誰會贏呢?當然是我們。」換言之,xAI 的策略想像並不局限於模型服務本身,而是試圖建立一個可與現實世界互動、並可延伸至車輛、機器人與其他終端載具的通用智慧平台。
6. 結語:一場競爭的核心,已轉向 AI 基礎設施與應用場景之爭
綜合來看,馬斯克的 AI 布局並不是零散投資,而是一套以資料來源、模型能力、運算平台與實體載具彼此串聯的閉環策略。從 X 提供即時語料,到 xAI 負責模型研發,再到 Tesla 承接物理世界的應用場景,這條路線的重點並不只是推出聊天產品,而是建立一個能從數位世界延伸到現實世界的 AI 系統。
在這個框架下, OpenAI 與馬斯克陣營的差異,已不只是開源或封閉的理念之爭,更涉及誰能率先把大型模型轉化為基礎設施與產業能力。這也使得雙方競爭的焦點,從單一產品比較,擴大為對下一代 AI 生態系的定義權之爭。
因此,理解這場競逐的關鍵,不在於支持哪一家公司,而在於看清不同技術路線將如何影響未來 AI 的開放性、控制權與落地方式。
(8) 從造車夢碎到 xAI 反攻:蘋果(Apple)最令人驚訝的五大策略轉向
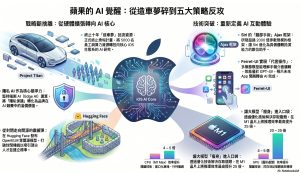
1. 前言:蘋果的沈默與覺醒
當 2023 年末全球科技巨頭如 Google、Meta、OpenAI 紛紛推出自家的大模型,展開激烈的 AI 軍備競賽時,一向站在科技浪尖的蘋果卻顯得格外「靜悄悄」。這份沈默讓外界不斷揣測:這家以追求完美體驗著稱的公司,是否在這場 AI 革命中失了先機?然而,進入 2024 年,蘋果終於打破沉默,以一系列大膽且出人意料的動作宣告回歸。這不只是產品的更新,更是這家科技巨頭在戰略航向上的重大修正。作為科技產業的長期觀察者,我認為蘋果正處於一個關鍵的轉捩點,正從「硬體導向」轉向「AI 為核心」的全新紀元。
2. 第一大轉向:捨棄十年的造車夢,重注 AI
2024 年 2 月,蘋果做出了科技史上最震撼的決定之一:正式終止代號為「泰坦計畫(Project Titan)」的電動車開發。根據內部消息,蘋果首席營運官傑夫·威廉姆斯(Jeff Williams)與負責該專案的副總裁凱文·林奇(Kevin Lynch)向約 5000 名員工告知了計畫終止的消息。分析與反思: 捨棄耕耘十年的領域絕非輕率之舉,這背後反映的是蘋果在面對大模型時代下的戰略收縮與重新聚焦。根據產業觀察,泰坦計畫之所以失敗,除了巨大的資源消耗外,更在於內部對於「L2 輔助駕駛」與「L4 全自動駕駛」目標的長期「搖擺」與不確定性。當 AI 大模型的浪潮席捲全球,蘋果意識到不能再將稀缺的算力資源與頂尖人才浪費在尚未成熟的造車場景中。放棄造車,是為了讓資源回流到更能直接鞏固其核心護城河——即 iPhone 與 iOS 生態系統的生成式 AI 研究上。蘋果執行長庫克曾表示自動駕駛項目是「所有人工智慧項目之母」,然而面對生成式 AI 的急迫威脅,即便是「項目之母」也必須為這場生存之戰讓路。
3. 第二大轉向:Siri 的「腦部手術」與 Ajax 模型
長期以來,Siri 的反應遲鈍與理解能力受限一直被用戶詬病。前蘋果工程師 John Burkey 曾公開批評,Siri 既有的架構基於繁瑣的「標籤式設計」,導致每增加一個基本功能都需要耗費數周重新構建資料庫,完全無法與現代基於 LLM(大語言模型)的助手相比。分析與反思: 為了徹底改寫 Siri 的命運,蘋果啟動了名為「Ajax」的大語言模型框架研發。Ajax 顯然是借鑒了 Google 的 JAX 框架(其名稱也由此而來),傳聞其參數規模超過 2000 億,目標是將 Siri 從單純的語音工具進化為具備理解力的人工智慧助手。這是一場「人機互動模式(HCI)」的典範轉移。當 AI 能執行複雜的跨 App 任務、摘要長篇文字,甚至是進行邏輯推演時,它將成為用戶與數位世界溝通的唯一入口,這對維持 iOS 生態系的黏著度至關重要。
4. 第三大轉向:讓大模型「瘦身」進入口袋
AI 大模型通常需要龐大的運算與記憶體空間,這對手持裝置來說是巨大挑戰。蘋果發布了一項關鍵研究,重點解決如何將模型數據從「閃存(Flash memory)」高效轉移到「記憶體(DRAM)」的技術瓶頸。分析與反思: 透過「窗口化策略(Windowing)」與「行列捆綁(Row-column bundling)」等優化技術,蘋果成功在 M1 Max CPU 上將推理效率提高了 4 到 5 倍。更令人驚艷的是,這項技術在 GPU(圖形處理單元)上的效率提升更高達 20 到 25 倍。這標誌著蘋果在「端側 AI(Edge AI)」領域的技術領先。對蘋果而言,「端側運行」不只是性能問題,更是隱私保護的關鍵。將運算留在本地,不依賴雲端,能讓「隱私」成為蘋果在 AI 競賽中與其他科技巨頭區隔開來的溢價特質。
5. 第四大轉向:Ferret-UI —— 懂手機介面的 AI
蘋果開發了一款名為「Ferret-UI」的多模態大模型,專門針對行動端用戶界面進行設計。它不只是理解文字,更能直接「看懂」螢幕上的所有 UI 元素,並理解圖示、按鈕與佈局之間的邏輯關係。分析與反思: Ferret-UI 最核心的突破在於「Anyres」技術。這項技術能將高解析度的螢幕內容拆解為子網格(Sub-grids),讓模型即使在處理微小的 UI 元素時,也能維持極高的精準度。測試數據顯示,Ferret-UI 在所有基本 UI 任務上的表現均優於 GPT-4V。這意味著 AI 未來將不再只是「回答問題」,而是能真正「代客操作」。當 AI 具備操作手機 App 的能力,我們或許正見證著「App 消失論」的開端——未來,用戶只需發出指令,AI 會在後台完成所有 App 間的跳轉與操作。
6. 第五大轉向:從封閉走向「開源」的震撼彈
蘋果一向以封閉的「圍牆花園」與嚴苛的保密協議著稱,但在 AI 競賽中,蘋果竟然在 Hugging Face 平台上發布了 OpenELM 模型,並連同 Ferret 專案一起向社區開源。分析與反思: OpenELM 提供了從 270M、450M、1.1B 到 3B 四種參數規模的模型,這在蘋果歷史上是極其罕見的動作。我認為這在某種程度上是蘋果的「無奈之舉」,因為在快速變動的 AI 領域,封閉的開發環境已成為吸引頂尖人才的絆腳石。透過開源,蘋果不僅能利用全球社群的力量加速技術迭代,更是在定義「高效能端側 AI」的標準。相比於其他巨頭爭奪「雲端大模型」的霸權,蘋果選擇在「樣本高效能訓練(Sample-efficient)」與「行動端適配」上開源,展現出其試圖在 AI 下半場後發先至的戰略調整。
7. 結語:蘋果的 AI 下半場才剛開始
2024 年是蘋果從「秘密研發」全面轉向「實戰佈局」的關鍵年。AI 已不再只是蘋果產品中的一項附加技術,而是決定其硬體帝國能否延續榮光的生死戰。從放棄造車到擁抱開源,蘋果展現出了前所未有的靈活性。最後思考: 當 AI 深度嵌入系統層面,我們熟悉的 iPhone 是否會演化為一個能自主思考、具備主動服務能力的全新生命體?蘋果正試圖將「隱私 AI」打造成一種用戶願意買單的進階權益。這場從封閉轉向開放、從硬體擴張轉向算法優化的豪賭,能否讓它在與 OpenAI 或 Google 的話語權競爭中重新奪回領先地位?這場關於定義未來的戰役,才剛剛揭幕。